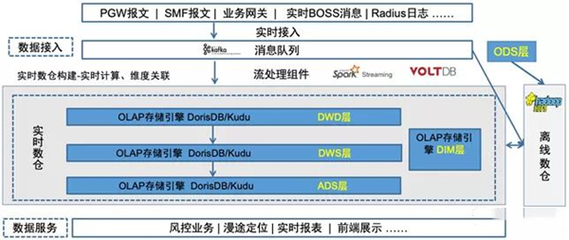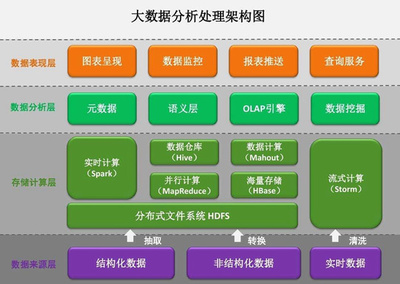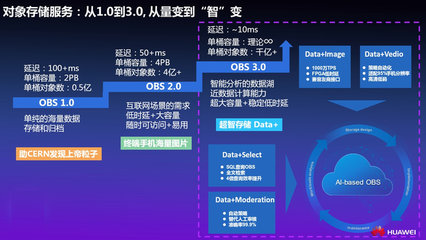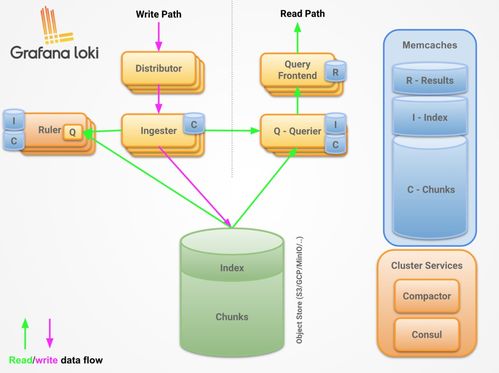
在当今数据驱动的时代,大数据存储与处理已成为企业数字化转型的核心引擎。Apache Hadoop生态系统作为开源大数据处理的基石,其资源管理与作业调度框架——YARN(Yet Another Resource Negotiator,另一种资源协调器),扮演着至关重要的角色。它不仅是一个高效的数据处理协调者,更是连接存储与计算的关键服务层。
一、YARN:大数据处理的“操作系统”
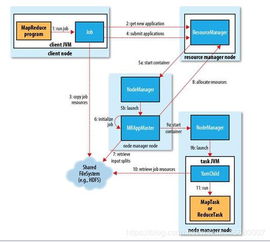
YARN最初作为Hadoop 2.0的核心组件被引入,旨在解决传统MapReduce框架在资源管理和扩展性上的瓶颈。它将资源管理与作业调度/监控功能分离,形成了一个通用的集群资源管理平台。YARN的核心架构包含三个关键组件:
- ResourceManager (RM):全局资源管理器,负责整个集群的资源分配与调度。
- NodeManager (NM):每个节点上的代理,负责管理单个节点的资源(如CPU、内存)并执行容器。
- ApplicationMaster (AM):每个应用特有的进程,负责与RM协商资源,并与NM协作以执行和监控任务。
这种分层架构使得YARN能够支持多种计算框架(如MapReduce、Spark、Flink等)在同一个集群上并行运行,实现了资源的高效复用与隔离。
二、YARN在数据处理中的核心作用
作为数据处理服务,YARN的核心价值体现在:
- 资源统一管理:YARN通过抽象的“容器”(Container)概念,将集群的计算资源(CPU、内存)进行统一池化管理。应用(如一个Spark作业)通过AM向RM申请容器,NM则在节点上启动这些容器来运行具体的任务(如Executor)。这种机制确保了多个应用可以公平、高效地共享集群资源,避免资源冲突和浪费。
- 多计算框架支持:YARN的通用性使其能够支持批处理(MapReduce)、交互式查询(Tez)、流处理(Storm/Flink)以及机器学习(Spark MLlib)等多种数据处理范式。企业无需为每种框架维护独立的集群,大幅降低了基础设施成本和运维复杂度。
- 弹性与可扩展性:YARN可以动态调整资源分配,根据作业优先级和集群负载进行弹性伸缩。它能够管理从几个节点到上万节点的大型集群,满足海量数据处理的需求。
三、YARN与大数据存储的协同
大数据存储(如HDFS、HBase、云存储服务)与YARN的紧密集成,构成了完整的数据处理流水线:
- 数据本地性优化:YARN调度任务时,会优先将任务分配到存储有所需数据块的节点上(“数据本地性”),从而减少网络传输开销,显著提升处理效率。这对于HDFS这类分布式文件系统尤其重要。
- 存储感知调度:YARN可以与存储系统(如HDFS)的元数据服务交互,感知数据分布,从而做出更智能的调度决策。例如,在处理时间序列数据时,可以将计算任务调度到存储最近写入数据的节点上。
- 统一资源视图:现代大数据平台中,YARN常与存储资源管理器(如HDFS的NameNode)协同工作,提供集群计算与存储资源的统一视图,便于监控和容量规划。
四、YARN作为数据处理服务的挑战与演进
尽管YARN已成为业界标准,但在实际应用中仍面临一些挑战:
- 资源模型相对简单:传统YARN主要管理CPU和内存,对GPU、FPGA等异构计算资源以及网络带宽、磁盘IO的支持仍在不断完善中。
- 实时性要求:对于低延迟的流处理作业,YARN的调度延迟有时可能成为瓶颈。社区通过改进如基于标签的调度、资源抢占等机制来优化响应时间。
- 云原生趋势:随着容器化(如Docker)和Kubernetes的兴起,YARN也在向云原生架构演进。例如,Hadoop 3.x支持在容器内运行YARN任务,而诸如Apache YuniKorn等项目致力于在K8s上实现YARN式的调度能力。
五、实践建议与未来展望
对于企业构建大数据平台,有效利用YARN数据处理与存储服务应考虑:
- 合理规划资源:根据工作负载特征(CPU密集型、内存密集型或IO密集型)配置YARN队列和资源配额。
- 监控与调优:利用YARN的监控API和工具(如Ambari、Cloudera Manager)持续跟踪资源利用率、作业性能,并调整调度策略(如公平调度器、容量调度器的配置)。
- 生态整合:将YARN与上层应用框架(如Spark on YARN)及底层存储系统深度集成,充分发挥数据本地性优势。
YARN将继续向更智能、更云原生的方向发展。与机器学习的结合(如基于预测的调度)、对混合云和多云环境的支持,以及更细粒度的资源管理能力,将使其在大数据存储与处理的生态中保持核心地位。
总而言之,YARN作为大数据处理与存储服务的关键协调层,通过其灵活的资源管理和多框架支持能力,赋能企业高效应对海量数据挑战。理解并优化YARN的部署与使用,是构建稳健、高性能大数据基础设施的必经之路。