在人工智能生成内容(AIGC)浪潮席卷全球的当下,高效、可靠的数据处理与存储服务已成为驱动技术创新的核心引擎。以王登宇先生为代表的前沿探索者,正致力于构建一套面向AIGC时代的综合性数据处理与存储解决方案,为海量非结构化数据的价值挖掘与智能应用提供坚实支撑。
一、AIGC数据处理:从原始素材到智能燃料
AIGC模型的训练与推理高度依赖于大规模、高质量的数据集。王登宇提出的数据处理方案,旨在将原始、无序的文本、图像、音频、视频等多模态数据,转化为模型可高效利用的“智能燃料”。该方案的核心流程包括:
- 数据采集与汇聚:通过合规渠道,广泛采集开源数据、合作方授权数据及特定场景的定制化数据,构建覆盖多领域、多语言的初始数据池。
- 数据清洗与标注:运用自动化工具与专业人工团队相结合的方式,对数据进行去重、去噪、格式标准化处理,并对关键内容进行精细化标注(如物体识别、情感分析、语义分割等),大幅提升数据的可用性与价值密度。
- 数据增强与合成:针对数据稀缺或样本不平衡问题,采用算法进行数据增强(如旋转、裁剪、色彩变换)或利用生成模型合成高质量的训练样本,以扩充数据集规模与多样性。
- 数据预处理与特征工程:根据特定AIGC模型(如大语言模型、扩散模型)的输入要求,对数据进行分词、向量化、归一化等预处理,并提取关键特征,为模型训练做好前端准备。
二、AIGC数据存储:安全、弹性、高性能的基石
处理后的数据需要被安全、高效地存储与管理,以支持模型的持续训练、迭代与在线服务。王登宇的存储解决方案聚焦于解决AIGC数据特有的挑战:
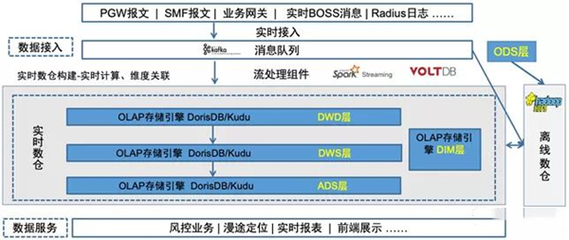
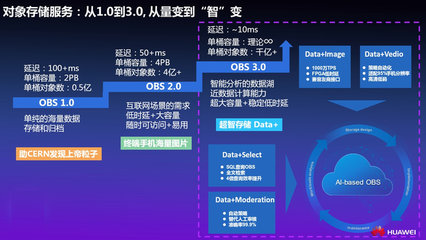
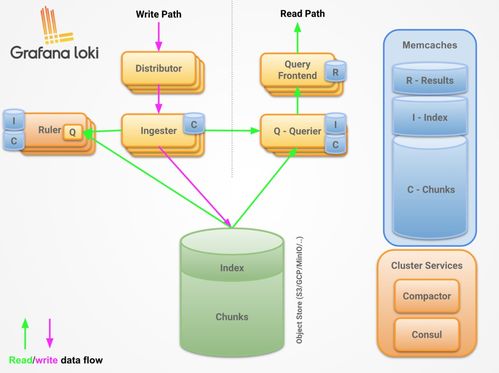
- 海量非结构化数据存储:采用对象存储服务,提供近乎无限的容量扩展能力,完美适配AIGC产生的海量图片、视频、模型参数等非结构化数据,支持高并发访问。
- 分级存储与生命周期管理:根据数据的热度(访问频率)和重要性,实施热、温、冷分级存储策略。将高频访问的训练数据置于高性能存储,将归档的旧版本模型或日志数据迁移至低成本存储,实现成本与效率的最优平衡。
- 高可用与数据安全:通过多副本、跨可用区部署确保数据的高可用性和持久性。集成加密存储(静态加密与传输加密)、严格的访问控制策略(RBAC)及合规审计日志,全方位保障数据安全与隐私,满足日益严格的监管要求。
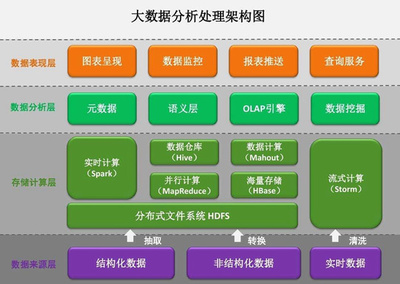
- 与计算框架无缝集成:存储系统与主流AI计算框架(如TensorFlow, PyTorch)及大数据处理平台深度集成,支持数据的高效加载与流水线作业,减少I/O瓶颈,加速模型训练与实验周期。
三、一体化服务:从数据到价值的端到端赋能
王登宇的解决方案不仅仅提供孤立的技术组件,更强调提供端到端的服务:
- 定制化数据处理流水线:根据客户特定的AIGC应用场景(如数字人创作、文案生成、代码辅助、艺术设计),设计并实施定制化的数据采集、处理与标注流程。
- 模型训练数据托管与版本管理:为模型训练提供专用的数据托管环境,并管理数据集的版本,确保实验的可复现性。
- 存储架构咨询与优化:针对客户现有的IT架构,提供AIGC数据存储的规划、迁移与性能优化咨询服务。
- 持续的技术支持与运维:提供7x24小时的技术支持与系统运维服务,确保数据处理与存储平台的稳定、高效运行。
###
在王登宇构想的AIGC数据处理与存储解决方案蓝图中,数据不再是静态的资源,而是流动的、可增值的核心资产。通过将先进的数据工程实践与云原生存储技术深度融合,该方案为AIGC的开发者和企业提供了从数据准备、管理到应用的全栈支持,有力降低了AIGC技术的应用门槛与运营成本,是推动AIGC在各行各业落地生根、释放巨大商业价值的关键基础设施。随着多模态大模型的持续演进,对数据处理与存储的智能化、实时性要求将更高,此类解决方案也将不断迭代,持续为AIGC生态注入强大动力。